Server-side Rendering: CDN and Caching

aka “The Other Servers”
Previously, I wrote about why Nebula decided to implement server-side rendering (SSR) for its web app and what it took to do so in the web app’s codebase. And now it's time to explain the last part of delivering server-side rendered pages to the browser — Content Delivery Network (CDN)
CDN
CDN is a network of proxy servers (also known as “edge” servers) all over the globe. These servers can:
- route users’ requests to different servers (for example, route dynamic
/jetlagto our SSR server and static/index.2c3.jsto S3 storage) - modify the HTTP headers that server receives from and sends to a browser
- run “serverless” functions (like AWS Lambdas)
- cache server responses
And, because they are all over the globe, your request for a video page doesn’t have to go under the ocean if there’s an edge server close to you and somebody else close to the same server has just loaded the same page
CDN has a huge impact on how optimized the server has to be — every request cached and served by CDN saves us a lot of server time. The Internet is crawling with bots, both benign and nefarious, so even if you aren’t operating at huge scale, at least some server caching (be it CDN or just a properly configured nginx/Caddy/whatever) will help dealing with those critters
There are several big companies providing CDN services, but nebula.tv uses Amazon’s CloudFront1. I will try to keep this post generic enough for developers outside of Amazon’s influence, but AWS specifics will pop up here and there
And by “here” I mean “here is some CloudFront’s terminology”:
- Distribution — a version of edge server configuration, used to route, cache, and other stuff for a specific domain
- Viewer request — original HTTP request coming from a browser or other client (native app,
curl, etc.) - Origin request — HTTP request sent from an edge server to wherever the distribution routes (aka “to origin”)
- Origin response — HTTP response from origin to an edge server
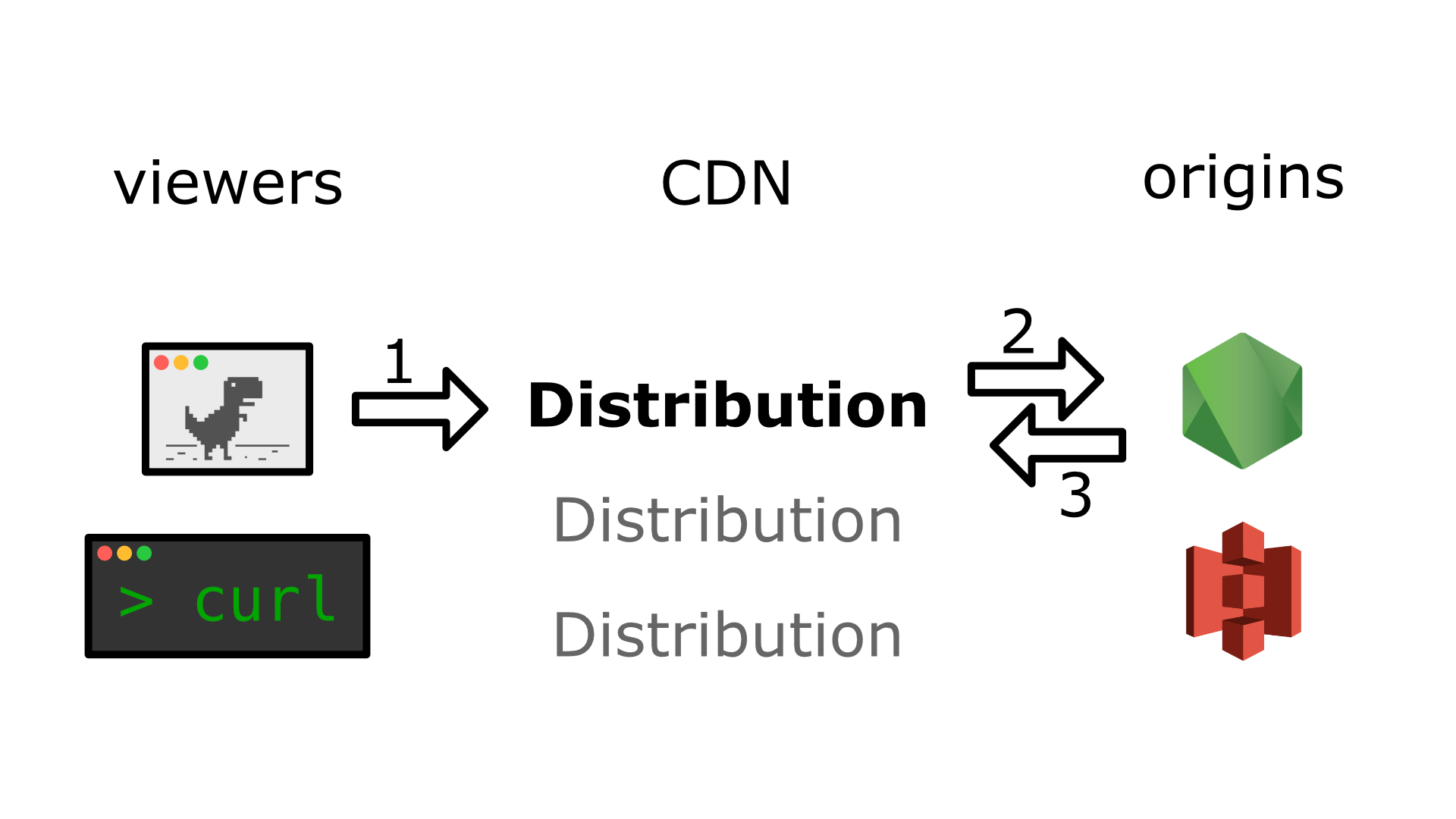
1. Viewer request
2. Origin request
3. Origin response
Caching
So, the main point of adding a CDN layer to your architecture is caching, but it isn’t limited to CDNs — browsers also cache2. In both cases, the caching is controlled by Cache-Control and Vary origin response headers
At its most basic, Cache-Control is an origin response header with a list of comma-separated directives:
max-age={number}indicates to both browser and CDN to cache the response to this URL and re-use it if there are viewer requests in the next{number}secondss-maxage={number}is similar, but for CDNs only — browsers just ignore itpublicindicates that response isn’t specific to a user/session, so can be stored in a shared cache- there’s also
no-cache,no-store,private,immutable, and others. The post is already getting long, so just read about those on MDN
Why would you want cache on CDN and not in a browser? Mostly3, to recover from errors — if server responded with broken code or data, and browser cached it for an hour, for that hour user will see the broken site4. On the other hand, if CDN has previously-broken-but-now-fixed response in its cache, there’s usually a button or an API to invalidate caches on edge servers, forcing them to load the latest version of whatever
While Cache-Control tells browser/CDN whether or not to cache a particular response, Vary tells what in viewer request will invalidate that cache. You see, by default, the browser’s “cache key” (identifier for data in cache) is the viewer request’s HTTP method and URL. But if a server can respond differently to requests with the same URL depending on viewer request headers (for example, user-specific data if there’s a session token in Cookie), these headers can be listed in Vary. Support for Vary header on CDNs is spotty — for example, CloudFront does understand it (albeit with some gotchas), CloudFlare basically ignores it5
AWS Specifics: Policies
if you aren’t interested in CloudFront minutia, you can skip to the next section
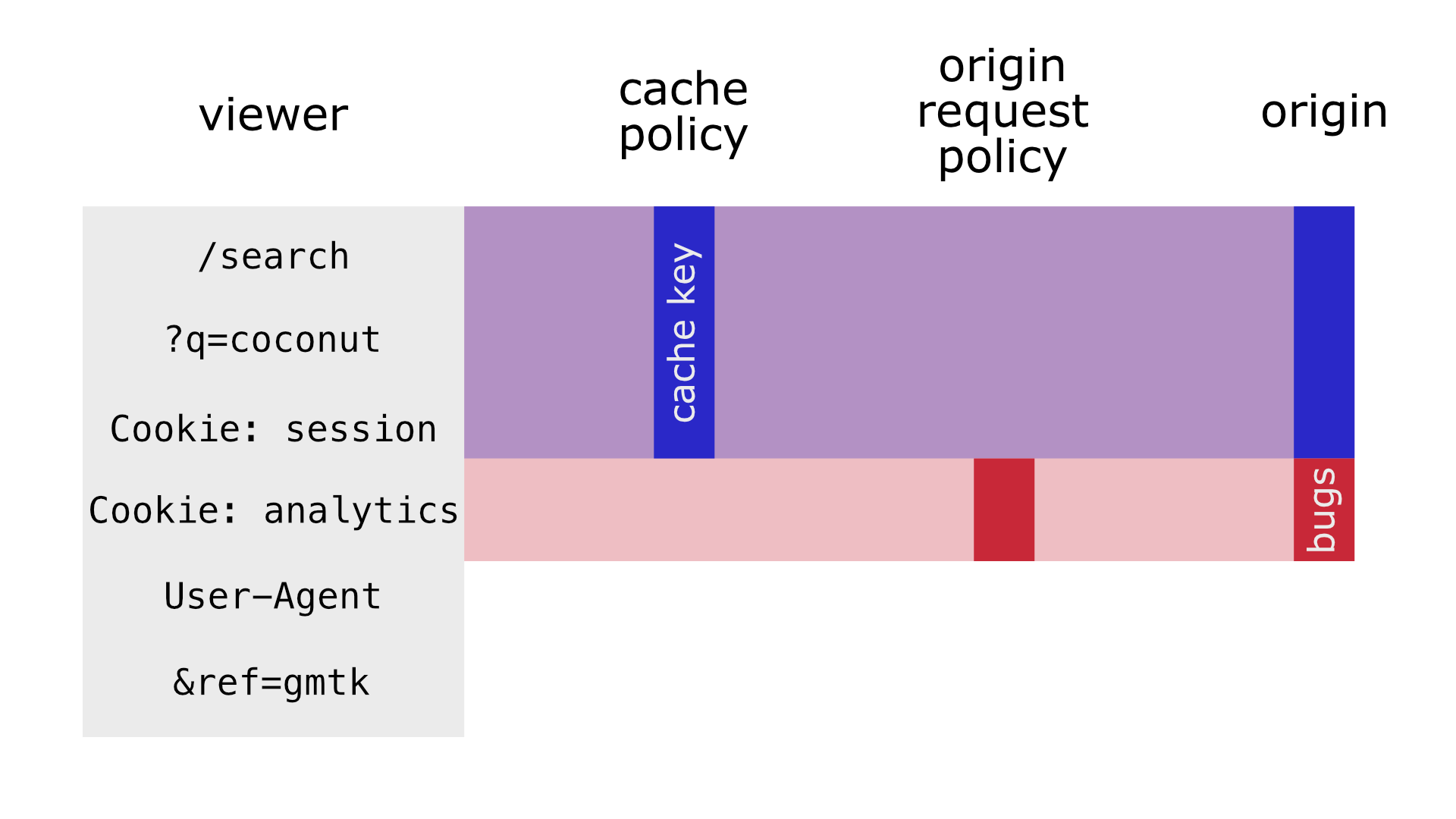
To better control the “cache key”, CloudFront has two “policies” that can finely tune distribution’s default and custom endpoints’ behavior
Cache policy describes what’s included in the “cache key” for each particular viewer request. By default, it's only URL pathname, but we can add all/allowlisted/blocklisted query params, headers, or cookies. For example, we can ignore fbclid and ref query param, and/or include only session cookie. That way these requests will have the same “cache key”:
https://nebula.tv/search?q=coconut
Cookie: session=patrick
https://nebula.tv/search?q=coconut
Cookie: session=patrick; analytics=dave-the-agent
https://nebula.tv/search?q=coconut&ref=gmtk
Cookie: session=patrick
Origin request policy describes what query params/headers/cookies have to be added to the request from CDN to SSR when the request's "cache key" is "missed" (= "not in CDN cache"). These query params/headers/cookies don't affect the “cache key", leading to possible issues — for example, if the cache policy ignores User-Agent header6, but the origin request policy includes it, Firefox users might get cached responses for Chrome, if Chrome was the first to hit a particular endpoint first. So use origin request policies very carefully
Everything outside of these policies won’t reach your server/origin
AWS has a list of predefined (“managed”) cache and origin request policies, which one can use by simply modifying the CloudFront distribution. If those aren’t enough for your needs, you can create your own
If you do create your own policy, avoid allowlisting query params. We learned the hard way that ignoring everything but a predefined list of params leads to nasty bugs if somebody7 forgets to update that list
What and How
What and how to cache depends a lot on your web app’s needs and what types of responses it serves. For nebula.tv, the needs are:
Public assets
In other words, version-controlled and uploaded as-is files, for example favicon.ico
We don’t cache those. Maybe, we should cache them on edge servers, but don’t — these files don’t block load of the web app, so S3 is fast enough
Built assets with hash in the filename
After a built tool (like vite) has done its job, output files usually have the file’s hash in their name (for example, 2c3 in index.2c3.js). Once the file is uploaded it’ll never change8, so both CDN and browser can cache it for a long time
So, when adding9 files like this to S3, we use --cache-control max-age=86400,public option of S3 cli
HTML responses with hardcoded metadata
These are HTML pages returned from SSR server that don’t change without a code deploy. In the case of Nebula, that’s pages like Classes or Videos
We don’t want to cache those in a browser, CDN can cache them for long10, and these pages don’t have data specific to a user
So, easy-peasy! When sending a response renderedHtml in SSR server, we’ll add Cache-Control with public and s-maxage:
res.writeHead(200, {
'Content-Type': 'text/html',
'Cache-Control': `public, s-maxage=${MAXAGE_IN_SECONDS}`,
});
res.end(renderedHtml);
Content-specific metadata HTML responses
Crap, I shouldn’t had used a constant in res.writeHead…
These are pages like a video page — it has, for example, the video’s thumbnail in <meta property="og:url"> and video creator can change that thumbnail whenever. To account for that, these pages are cached for five minutes. Yeah, it isn’t instantaneous, but it also doesn’t complicate our content management system (CMS) with “cache invalidation” API calls to CloudFront
To change the default MAXAGE_IN_SECONDS for these pages, we’re using the context property of React Router’s <StaticRouter>11. This property is an object that gets automatically passed to route components as staticContext and can be modified in those components. So, whenever a page includes CMS-defined metadata, we’re passing a smaller value for s-maxage via that object:
// server.jsx
const routerContext = { cacheDuration: undefined };
const renderedHtml = ReactDOMServer.renderToString(
// ...
<StaticRouter location={url} context={routerContext}>
<App />
</StaticRouter>
// ...
);
res.writeHead(200, {
'Content-Type': 'text/html',
'Cache-Control': `public, s-maxage=${routerContext.cacheDuration ?? MAXAGE_IN_SECONDS}`,
});
res.end(renderedHtml);
// pages/Video.jsx
const STATIC_CACHE_DURATION = 300; // 5 minutes
export function Video({ staticContext }) {
if (staticContext) {
staticContext.cacheDuration = STATIC_CACHE_DURATION;
}
// ...
}
Error responses
But that’s when everything goes smoothly. But it never not always does
If something goes “wrong”, for example user loads a video page a minute before it’s published, we don’t want to serve cached 404 error for the next four minutes. So treat responses with 4XX or 5XX HTTP codes differently — either don’t cache them entirely, cache them for a shorter time, or something
AWS Specifics: Failover
Once again, click here to skip
CloudFront has a notion of failover, for when the origin can’t be reached or if it returns some error code. SPAs frequently use fallbacks for a client-side routing: CloudFront receives a request for /something, goes to SSR, gets a HTTP 500 from it, and falls back to serving /index.html, which is (hopefully) present on S3
nebula.tv uses fallbacks to hide 5XX errors from users by doing basically the same — if SSR can’t be reached (HTTP 502) or can’t process the request due to code error (HTTP 500), it’ll just serve index.html from S3. That way, SSR errors only affect bots while humans visitors will have the same experience as before12
// cloudfront-distribution.json
{
// ...
"CustomErrorResponses": {
"Quantity": 2, // oh yeah, CloudFront can't count `Items` by itself
"Items": [
{
"ErrorCode": 500,
"ResponsePagePath": "/index.html",
"ResponseCode": "500",
"ErrorCachingMinTTL": 0
},
{
"ErrorCode": 502,
"ResponsePagePath": "/index.html",
"ResponseCode": "502",
"ErrorCachingMinTTL": 0
}
]
}
}
While this is quite handy, it does create problems with JSON endpoints on the same distribution — if such endpoint returns HTTP 500 with some data in JSON response, CloudFront will helpfully replace that response with index.html. Not sure how to solve that, but maybe something will come up…
How it went
After all that work was done, I think it was worth it:
- requests with warm13 CDN cache sped up from 1-1.5 seconds to 20-50ms
- Google discovered that Nebula has videos
- more messengers started to show nice link previews
- the server component specifically for the web app is great to have in the tool belt14
Although, requests with cold CDN caches — loading an unpopular page can take seconds to finish. At some point, I hope we’ll skip more API requests on the server and/or share the React Query cache between SSR processes, but not today
Thank you
Thank you for your attention. If you liked these posts, please consider supporting Ukraine
Thanks to Sam Rose for the help with writing this. Photo by Taylor Van Riper
Also Fastly and, since recently, CloudFlare, but that’s not important for this post ↩︎
As well as servers, databases, processors, and almost everything else computer’y, but don’t worry about that now ↩︎
And, less mostly, to better control when new features become accessible ↩︎
If you’re looking for a comment section to type out “But they can reload with cache disabled!”, don’t bother ↩︎
Do I hate that two CDNs we’re using share the “CF” abbreviation! ↩︎
Which is a good idea, since this header rarely affects the HTTP response but has so many variants that cache will rarely be warm ↩︎
Assuming there are no hash collisions ↩︎
Because we want to have older assets available to avoid 404s if browser has stale cache or if we did a version rollback ↩︎
Although, nebula.tv caches them for a day, which is longish, but not that long. Can’t remember why… Maybe, just to be safe?.. ↩︎
We’re still on
react-router@5because, until recently, the sixth version had a few issues that made it harder to migrate without a performance hit ↩︎Unless they are developers who browse with an open Web Inspector 😅 ↩︎
Cache is warm when it has data to respond without reaching to the origin, and cold when it doesn’t and needs to wait on the origin to respond ↩︎
For example, to have a better experience for feature toggles — client-side-only web app has to wait on fresh flags to load. Or risk the UI flashing ↩︎