Server-side Rendering: Backstory

About implementing SSR at Nebula
Where I write about the project few months after the fact
It all started before I’ve joined Nebula. During my job interview there, we’ve discussed benefits and problems of Nebula being a single page application. I, who spent some time dealing with Open Graph for link previews, raised the point that naively implemented, all pages would have the same metadata, which isn’t great for SEO or social sharing. Yeah, Google has enough servers to run JS and compute page’s <title> and <meta> tags, but I doubted that that’s the case for all messengers, social networks, and blogs1
But Twitter and Slack did show those links with nice thumbnails and stuff. Maybe, social networks do run client-side code for Open Graph?..
Aside: some basics
Nebula is a video and podcast streaming service with clients on several platforms. All of them are built on top of common HTTP APIs, some (like Content) are maintained by Nebula team, some (like payments) are third-party
Web version is a React application that uses React Router for rendering the correct page content depending on the URL and React Query for dealing with HTTP APIs. The application consists of static files, that are built once during release, uploaded to S3, and served to visitors via CloudFront CDN
So, back to social networks. Do they run JS to compute Open Graph data?
Nah
Nope, they don't. How, then, was Twitter showing thumbnails in Nebula's link previews? Well, CloudFront distribution from a few lines before wasn’t only serving static files. It also checked request’s User-Agent header and, if it matched the /bot|crawler|spider|crawling|facebook|twitter|slack/i regex, would forward the request to a nebula-meta server application, which would do necessary requests to Content API and return a barebones version of the page, without any client-side code but with URL-specific <title> and <meta>:
-
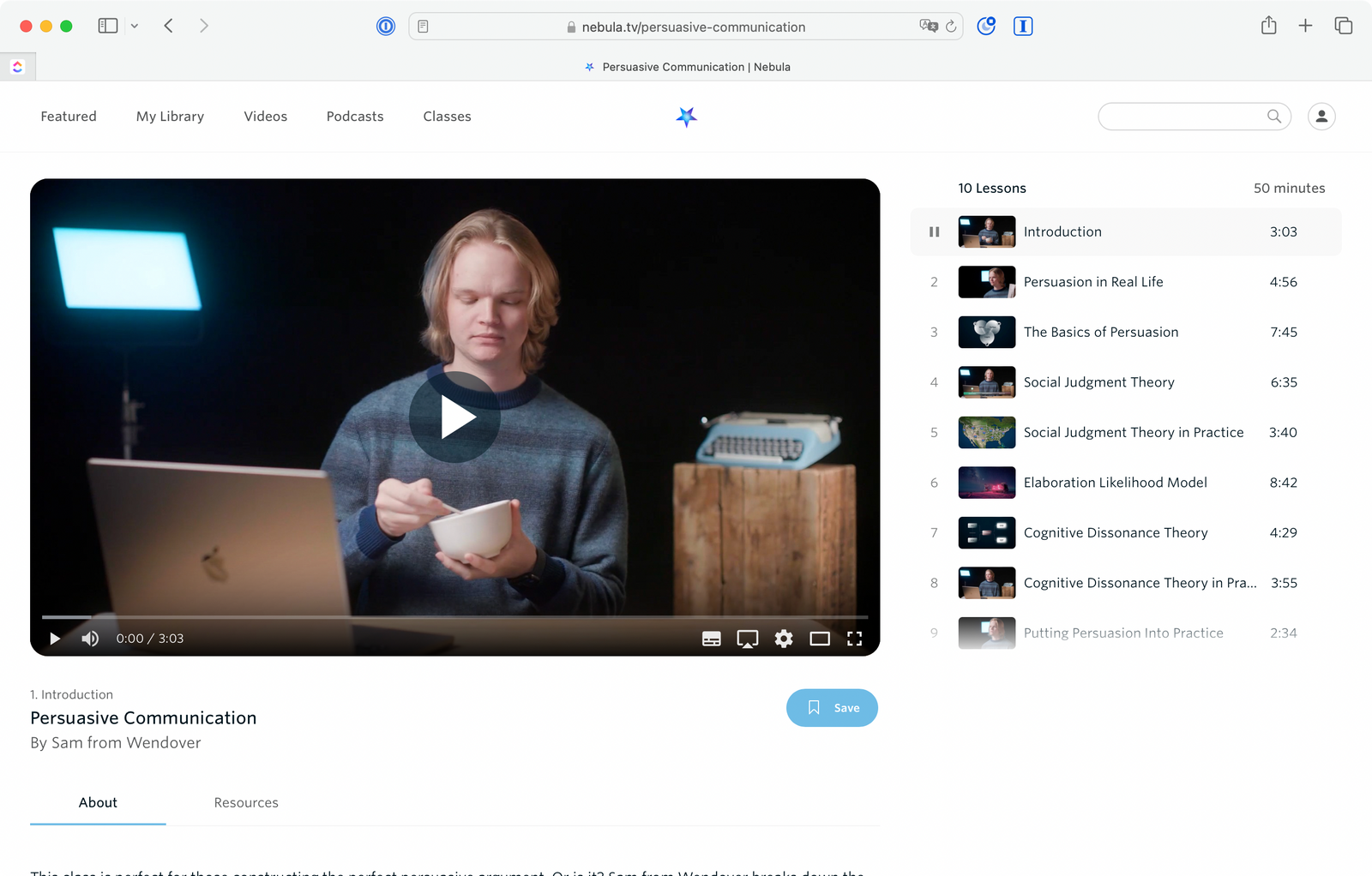
Nice class page for humans -
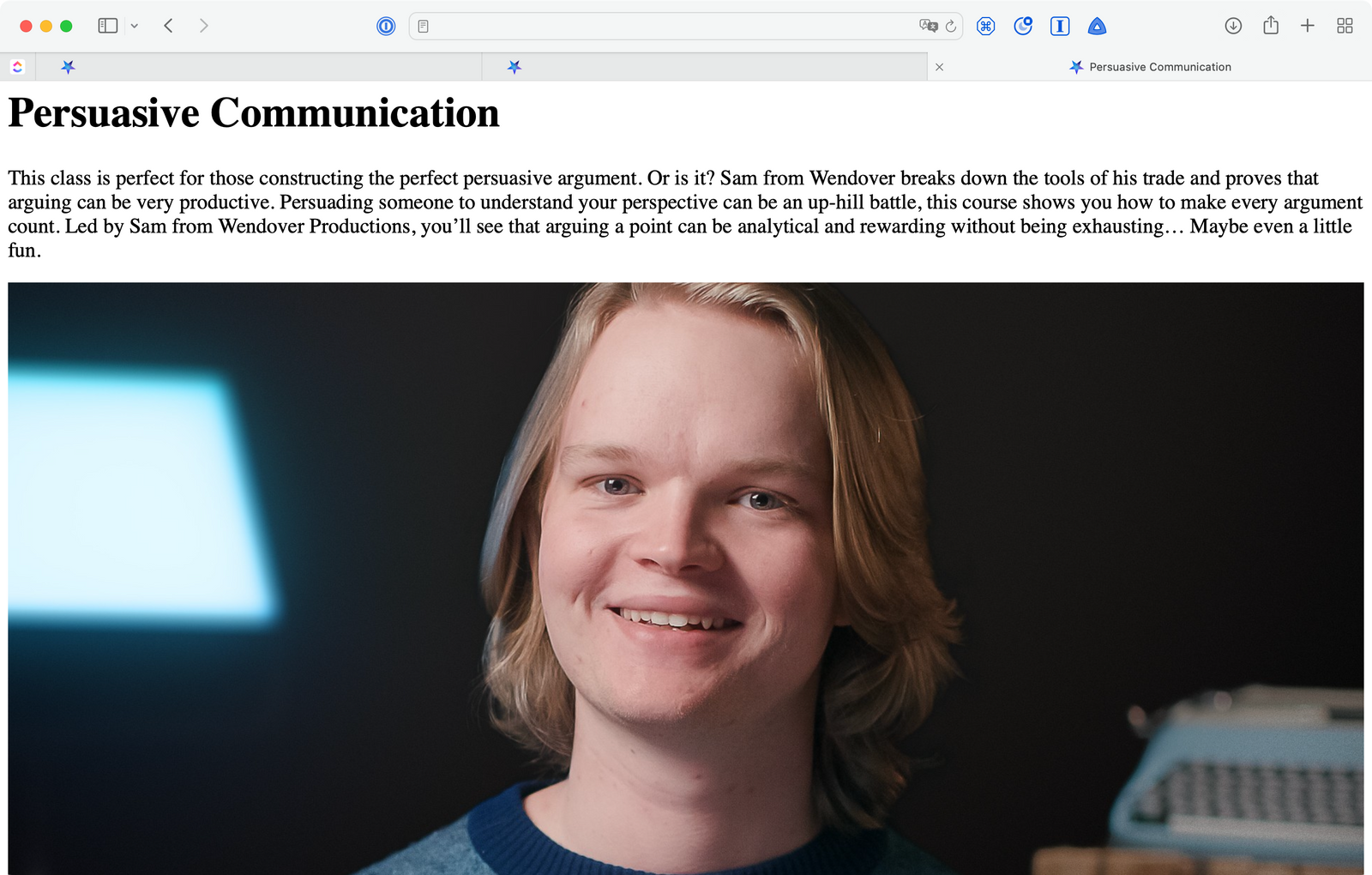
Brutalist class page for bots
The fact that nebula-meta existed was largely forgotten, because APIs still worked, Open Graph didn’t change, and its original developer moved on to other parts of the company. But keeping it was problematic:
- when
metawas originally written, Content API was a third-party one (let’s call it Y). Since then, the API became first-party, but we still uploaded images and descriptions to Y, which, at some point, had lead to a head-scratching “stale thumbnail” bug - it knew nothing about then-upcoming Nebula Classes
- it knew nothing about WhatsApp, Telegram, random blogs, and other crawlers that might be interested in Open Graph data
- it knew nothing about
/.well-known/URLs, that both Android and iOS use to associate domains with applications (for things like password suggestions, deeplinks, and SharePlay) - having a separate codebase for bot requests just asks for bugs
What then?
So we’ve decided to:
- start rendering application's pages on a server (i.e. implement Server-side Rendering aka SSR) to keep crawler data in sync with browser data, and to make it easier to tweak and to test crawler-first parts of the site
- quickly fix small but critical things in
metabefore diving into1. - disable
metaafter first two points are done
Doing the 2. was a good idea not only because we'll make visible improvements sooner, but also because most of this post was happening in winter of 2021/2022 and russia's invasion of Ukraine would move dates a bit
In the next part I’ll talk about how SSR was actually done
Thank you for your attention
it for sure isn’t for this blog ↩︎