Усатый ядерщик

Are there good parts inside an abandoned project? What could we learn from it? Could we apply some patterns in our current projects?
Выковыривая полезные идеи из заброшенного модуля
Адаптировано из выступления “React with mustaches” на React Kyiv (видео и слайды)
Бывает так, что гоняешься не за тем, за чем стоило бы. В разработке, это зачастую выражается в странных решениях временных или надуманных проблем. Для таких решений пишется код, который либо никогда не увидит продакшена, либо довольно быстро будет удалён за ненадобностью
Повезёт, если такой код поможет не только тебе
Но повезёт ещё больше, если кроме одноразового кода останется опыт, который поможет решить более стоящие проблемы
Проблема
Проект, над которым я тогда работал, использовал Python на бекенде и React на фронтенде. Из-за SEO и почтительного возраста кодовой базы, React использовался не для SPA, а для progressive enhancement — бекенд, на основе Mako-шаблонов, отдавал HTML со полным контентом страницы
А фронтенд, на основе JSX, поверх этого контента рендерил интерактивные элементы. Так как серверные и клиентские шаблоны шаблоны были написаны на разных языках, разработчики повторяли приблизительно один и тот же HTML в Mako и в JSX. И, конечно же, когда правили шаблоны на одном языке, часто забывали повторить изменения на другом
Проблема не то, чтобы критическая — небольшой content flash, для частного фикса которого надо всего-то немного покопипастить. Но она генерировала достаточное количество баг-репортов, чтобы показаться заслуживающей более основательного решения
Для SSR-инфраструктуры на NodeJS’е, на тот момент, ещё не созрели. Так что решили попробовать другой подход
План
Мы подумали: а что если вместо разворачивания NodeJS-серверов, попробуем писать интерактивные элементы на общем языке, понятном и на существующем бекенде, и на фронтенде? Тогда обе части стека смогут использовать одни и те же исходники шаблонов. Общие исходники -> ничего не надо повторять вручную -> меньше однообразных баг-репортов
def render_navigation():
return (
"<div data-nav>" +
render("navigation.tmpl") +
"</div>"
)
import Nav from "navigation.tmpl"
function hydrateNavigation() {
for (let n of document.querySelectorAll("[data-nav]")) {
ReactDOM.hydrate(<Nav />, n)
}
}
За общий язык шаблонов выбрали mustache. Модули для рендера mustache-шаблонов написаны на куче языков (а то и по несколько раз), а сами шаблоны — простые как пробка. В них нельзя описать логику на другом языке (в отличии от, к примеру, JSX, в котором можно писать вставки со сложными JS-выражениями). Плюс, язык шаблонов довольно подробно описан в короткой спецификации, с примерами и на человеческом языке
Несмотря на наличие рендеров на куче языков, они все отдают результат в виде обычной строки. Нам же, в идеале, надо рендерить шаблоны в React-код, чтобы не рисковать XSS из-за dangerouslySetInnerHTML и чтобы не терять оптимизаций, связанных с виртуальным DOM
Рендерить шаблоны в код решили с помощью кастомного webpack loader’а. Лоадеры уже использовались на проекте для штук вроде импорта CSS-файлов, так что добавление ещё одного не станет проблемой
В итоге, мы хотели попробовать написать такой лоадер, который компилировал mustache-шаблоны в эквивалентный React-компонент. За target выбрали ES3 с вызовами React.createElement, чтобы избежать дополнительной компиляции бабелем:
// `<a href={{ href }}>{{ label }}</a>`
var React = require("react")
module.exports = function (props) {
return React.createElement(
"a", { href: props.href }, props.label
)
}
И написали. Обозвали schwartzmanом (как актёра), залили на гитхаб и использовали в продакшене
Прежде, чем продолжать… Да, это странное и, в каком-то смысле, overcomplicated решение проблемы SSR. Но это решение:
- не станет проблемой, когда появится NodeJS-инфраструктура,
- не потребует переписывания всего стека (новый язык шаблонов дружит с Mako на бекенде и с JSX на фронтенде)
Да и я не надеюсь что вы будете использовать лоадер у себя. Даже не так. Надеюсь, что вы не будете использовать лоадер у себя
Ладно, адресовав возможные “ты говно и идея твоя говно”…
Парсинг
Изнутри, как и многие компиляторы, schwartzman работает в два этапа: “парсинг” и “генерация кода”. На первом этапе, лоадер преобразовывает строку с исходными кодом в объект с синтаксическим деревом
Regex
Первым делом, при написании парсера, хочется воспользоваться регулярными выражениями. Но это плохая идея по двум причинам:
- у нас слишком много правил для того, чтобы итоговая регулярка была читаемой
- нам надо парсить HTML. Я не буду вдаваться в подробности почему “парсить HTML регулярками” — это плохая идея; в интернете достаточно объяснений
Custom lexer + parser
Можно написать кастомные лексер (который разбивает строку на подстроки) и парсер (который собирает синтаксическое дерево из этих подстрок), чтобы процесс был максимально оптимизированным под наш синтаксис. Но это сложнааа, лень, триггерит воспоминания об универе, да и довольно бесполезно, потому что есть…
Parsing expression grammar
“Грамматика, разбирающая выражения” или “PEG”. Разработчик описывает синтаксис языка именованными правилами, из которых потом генерируется парсер этого самого языка
Например, так может выглядеть грамматика для подмножества HTML, в котором есть только два тега, <i> и <b>, и нет никаких атрибутов:
grammar bitsy
node <- tag / text_node
tag <- i_tag / b_tag
i_tag <- "<i>" node* "</i>"
b_tag <- "<b>" node* "</b>"
text_node <- [^<>]+
Для генерации парсера из PEG-файла есть несколько библиотек
Самая “знаменитая”, на мой взгляд, это ANTLR, она довольно зрелая, умеет генерировать грамматику в JS, но для работы требует Джаву…
Из библиотек на JS, в 2015 год выбор был из Canopy и очень оригинально обозванной PEGjs. Выбрал, в итоге, первую. Не помню, по какой причине1, но не столь важно…
Важно то, что определившись с модулем для парсинга PEG, я мог начать постепенно описывать синтаксис для “HTML с mustache-вставками”, начав с корня дерева и добавив
- хелперы, которые очистят дерево от всякого мусора
- новые типы нод, разделив их на “HTML-элементы”, “
mustache-теги” и “plain text” - произвольные имена тегов и функцию для валидации их сбалансированного открытия/закрытия, чтобы можно было сгенерировать валидные вызовы
React.createElement - прочий синтаксис…
grammar Schwartzman
root_node <- expr_node* %strip_whitespaces
dom_node <- (open_html_tag expr_node* close_html_tag) %validate <DOMNode> / contained_html_tag <DOMNode> / commented_html <CommentedDOMNode>
open_html_tag <- "<" whitespace? tag_name whitespace? attrs:dom_attr* whitespace? ">"
contained_html_tag <- "<" whitespace? tag_name whitespace? attrs:dom_attr* whitespace? "/>"
После того, как перечислил все кейсы, мог сгенерировать модуль с функцией parse, которая:
- словит ошибки в шаблоне и кинет относительно читабельное сообщение. Например, если разработчик не сбалансировал теги (то есть, закрыл родительский тег до того, как закрыл все дочерние)
- если шаблон ок, то отдаст готовенькое синтаксическое дерево
require("./grammar.js")
.parse("<b>hello, <i>world</i>!</b>")
/* =>
TreeNode {
text: '<b>hello, <i>world</i>!</b>',
offset: 0,
elements:
[ TreeNode { text: '<b>', offset: 0, elements: [] },
TreeNode {
text: 'hello, <i>world</i>!',
offset: 3,
elements:
[ TreeNode { text: 'hello, ', offset: 3, elements: [Array] },
TreeNode { text: '<i>world</i>', offset: 10, elements: [Array] },
TreeNode { text: '!', offset: 22, elements: [Array] } ] },
TreeNode { text: '</b>', offset: 23, elements: [] } ] }
*/
Генерация кода
Имея синтаксическое дерево, лоадер может приступить к генерации React-кода
Упрощённо, лоадер выглядит как-то так:
function loader(content) {
const tree = parse(content)
const { code } = compile(tree)
return `var h = require("react").createElement
module.exports = function (props) { return ${code} }
if (
typeof process !== "undefined"
&& process.env
&& process.env.NODE_ENV === "test"
) { /* … */ }`
}
Лоадер получает содержимое шаблона как строку, парсит его в синтаксическое дерево, передаёт получившееся дерево в функцию compile, которая сгенерирует код компонента
Получившийся код компонента заворачивается в бойлерплейт с экспортом, дебаг-информацией для тестирования, и коротким именем для createElement
Внутри compile, лоадер рекурсивно проходится по синтаксическому дереву и возвращает объект с кодом и некоторой дополнительной информацией про контекст:
function compile(node) {
const { tag_name, attrs, elements } = node
const children = compileChildren(elements)
const compiledAttrs = compileAttrs(attrs)
return {
code: `h("${tag_name}", ${compiledAttrs}, ${children})`,
// …
}
}
Реальный код сложнее, так как нам надо обрабатывать кучу ограничений React’а и mustache’а
Escaping
Например, в mustache есть “обычная” замена переменной, которую можно скомпилировать в приблизительно такой React-код. По спецификации, HTML эскейпится при “обычной” замене, что совпадает со стандартным поведением childrenов в React’е
// `<div>{{ mark }}</div>`
React.createElement(
"div", null, props.mark
)
Для замены без эскейпинга, в mustache есть специальные теги {{& и {{{. Сами по себе, эти теги не вызывают проблем — просто генерируем больше кода и делов-то
// `<div>{{& mark }}</div>`
React.createElement(
"div", {
dangerouslySetInnerHTML: {
__html: props.mark
}
}
)
Но в Реакте, dangerouslySetInnerHTML — это свойство элемента (а не его дочерних нод), так что как только в шаблонах начинают комбинироваться теги без эскейпинга с любыми другими тегами или нодами, то лоадер должен это как-то обрабатывать:
<div>
<i>{{ john }}:</i>
oh, hi {{& mark }}
</div>
Можно было бы эскейпить соседние ноды “руками”. Но это сложнааа, потому что тогда надо перегенерировать код всей родительской ноды и её заэскейпленных childrenов
Так что остановился на другом варианте и ограничил количество дочерних нод, если хотя бы одна из них заэскейпленная. Всё равно отключение эскейпинга не поощряется…
if (children.length === 1 && children[0].escaped) {
// add some `danger`
} else if (children.some(c => c.escaped)) {
throw new OneChildPolicy()
}
{{# section }}
Но не только react усложняет написание лоадера, но и сам mustache…
Несмотря на то, что mustache называет себя “logic-less”, в нём есть пара тегов, которые по тому или иному условию рендерят своё тело
Первый, invert, работает как if not — тело тега рендерится, если значение в контексте либо falsey, либо пустой массив. Для этого тега несложно сгенерировать код, который будет отдавать правильный контент в зависимости от значений в props:
// `<b>{{^ great }}Not terrible{{/ great }}</b>`
React.createElement(
"b",
null,
(!props.great || !props.great.length)
? "Not terrible"
: null
)
Второй же “условный” тег, также известный как “секция”, выполняет кучу ролей, каждая из которых зависит от значений в контексте. Например, для шаблона <div>{{# user }}{{ name }}{{/ user }}</div>:
- Если
user— это булевое значение, то секция работает какif, а шаблон можно скомпилировать в элементReact.createElement("div", null, props.user ? props.name : null) - Если
user— это объект, то секция работает какscope(илиnamespace), “ограничивая” доступ кprops. В итоге, шаблон можно скомпилировать в элементReact.createElement("div", null, props.user ? props.user.name : null)
Только в рантайме компонент может знать, откуда доставать name — из корня props или из вложенного объекта user…
Так что лоадер, кроме вызовов React.createElement, также должен добавить в код рантайм-хелперы
Один из таких хелперов — это функция для поиска значения в контексте, которой передаётся список возможных “скоупов” (в нашем случае это ["user"]), и ключ, который нужно найти (name). Если же ключа нет, то, по спецификации, заменяем тег на пустое значение
Другой хелпер помогает с двумя другими “ролями” секции:
- Если в
propsпередан массив, то секция работает какfor_eachи повторяет своё тело для каждого элемента этого массива - Если в
propsпередана функция, то секция работает какlambdaи рендерер заменят тело секции результатом вызова функции
Логика для проверки “роли” секции становится слишком сложной, так что выносим его в хелпер-функцию section. Она находит значение секции в props и, в зависимости от его типа, отдаёт соответсвующее React-дерево:
return `function section(/* … */) {
var obj = scopeSearch(/* scope section */)
if (obj) {
if (isArray(obj)) {
// for_each section
} else if (isFunction(obj)) {
// lambda section
} else {
// if section
}
}
}`
Самое интересное начинается, когда секция выполняет роль “лямбды”. Потому что, по спецификации mustache, функция в такой секции:
- может вернуть строку с HTML
- принимает в аргументах тело секции и функцию для рендера своего тела с правильными скоупами переменных
Так что нам нужен волшебный хелпер, который в рантайме из HTML-строки сгенерирует React-дерево. Этим хелпером является сам schwartzman. Так что лоадер, при генерации кода, должен включить сам себя в результат, чтобы React-компонент мог заevalить2 результат и отдать другой, скомпилированный в рантайме, компонент:
return `function render(/* … */) {
var lowLevel = require("schwartzman").lowLevel
var parsed = lowLevel.parse(/* … */)
// …
return eval(lowLevel.compile(parsed))
}`
Удобства
Ограничения mustache влияют не только на то, что мы должны делать при обработке секций, но и на то, что можно делать. Например, нельзя расширить синтаксис штуками вроде явно именованных элементов массивов:
{{#users u}}
{{ u.name }}
{{/users}}
Нам надо соблюдать совместимость с mustacheм на бекенде, а он не знает ничего про особую роль пробелов в названии секции
В первых версиях лоадера, до меня это не дошло, так что я попытался добавить поддержку именованных элементов массива. Только чтобы откатить всё обратно, когда renderer mustacheа на бекенде не мог найти непонятные ключи в контексте
Хотя, это и хорошо, что необходимость совместимости не пускала сильно далеко. Потому что вместо траты времени и усилий на разработку и поддержку неважных фич, можно было вкладываться в удобство использования лоадером
Demo-страница
Одним из таких удобств была demo-страничка, на которой можно вбить шаблон и контекст, и получить отрендеренный компонент с его кодом. Идея, конечно, далеко не оригинальная, но всё ещё недостаточно распространённая, как на мой взгляд
Сначала мне казалось, что сделать такую страничку будет сложно из-за того, что надо будет возиться с зависимостями и с отличиями между окружениями NodeJS (в котором лоадер крутился до этого) и браузера (в котором будет крутиться демо-страничка)
Но, когда начал перечислять все зависимости, всё оказалось намного проще:
- Из пакетов:
- сгенерированный код зависит только от React’а (и то опционально) и от самого лоадера для обработки
{{# lambda }}-секций - а лоадер — только от функции для парсинга вебпаковских настроек
- сгенерированный код зависит только от React’а (и то опционально) и от самого лоадера для обработки
- Про ноду, лоадер и сгенерированных код знают очень мало:
- что зависимости получаются вызовом функции
require - и что в окружении есть
module.exportsиprocess.env.NODE_ENV
- что зависимости получаются вызовом функции
var h = require("react").createElement
var lowLevel = require("schwartzman").lowLevel
var parseQuery = require("loader-utils").parseQuery
module.exports = function (content) { /* … */ }
if (
typeof process != "undefined"
&& process.env
&& process.env.NODE_ENV === "test"
) { /* … */ }
Все эти зависимости легко замокать вручную, избежав возни с бандлерами и дополнительным build-степом для демо-страницы:
window.module = {}
window.process = { env: { NODE_ENV: "test" } }
window.require = function (name) {
if (name === "loader-utils") {
return { parseQuery() { return {} } }
}
if (name === "react") {
return /*
<script src="https://unpkg.com/react@16/umd/react.production.min.js"></script>
*/
}
if (name === "schwartzman") {
return /*
<script src="https://unpkg.com/schwartzman"></script>
*/
}
}
Причём, parseQuery (функцию для парсинга вебпаковских опций) можно полностью заменить на свою реализацию, которая всегда будет отдавать одно и то же. А реакт и лоадер можно тянуть с unpkg
Существование этой странички очень помогло с баг-репортами, особенно когда начал прописывать входные шаблон и props в URL
Так что если лоадер падает или странно рендерит шаблон, его пользователи могли кинуть ссылку на проблемный шаблон в Slack или Github Issues. Так что и для юзеров есть чёткий flow для жалоб, и я могу сэкономить время на написание тест-кейсов. Так что да, чем меньше модуль знает, тем лучше
Тестирование зависимостей
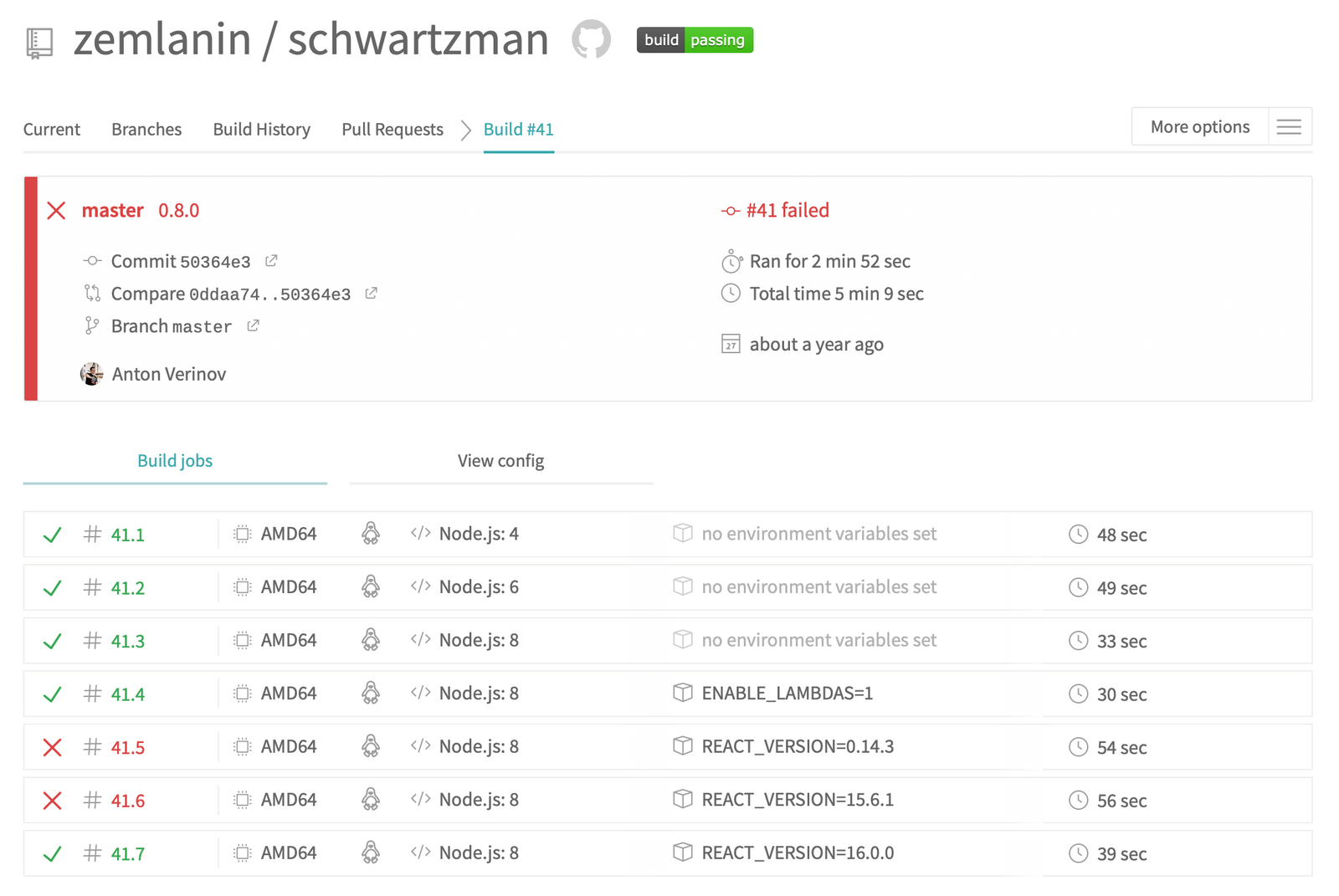
Прошло два года. Лоадер продолжал использоваться то тут, то там, так что я добавляю тесты на сгенерированный код и отрендеренный им статический маркап, плюс периодически проверяю совместимость с новыми версиями Реакта
Переход на пятнадцатую версию не вызвал никаких проблем, а вот с выходом шестнадцатой билд становится красным…
<div style="color: red;">hello world</div>
<!-- ^ ^ -->
<div style="color:red">hello world</div>
Дело в том, что шестнадцатый ReactDOM поменял то, как форматируются inline-стили, так что тесты на отрендеренный шаблон начали падать. Передо мной предстал выбор:
Либо переписать тесты на шестнадцатый React
Для лоадера с малым количеством кода и достаточным количеством тестов это довольно быстро, но, по сути, сделает лоадер совместимым только с последней версией React’а. Потому что вдруг что-то поломается в совместимости с прошлой версией, а помнить проверять всё ручками я не могу
Для пользователей же лоадера, обновление их основной UI-библиотеки — дело намного более муторное
Лиииибо я мог бы добавить в тесты проверки на версию React’а и ожидать соответствующие результаты в тест-кейсах
Пользователям это дико упрощает миграцию — они могут обновлять React и лоадер без привязки друг к другу
Мне же нужно описывать отдельные тест-кейсы для разных React’ов и как-то устанавливать с npmа правильные версии зависимостей перед прогоном тестов, а это сложнааа. Но, так как я уже дважды выбирал простой путь, так что пора выбрать и сложный…
Поэтому пишем в тестах ожидания, зависящие от версии React’а3
const rendered = semver.gte(React.version, "16.0.0")
? `<div style="color:red">red</div>`
: `<div style="color:red;">red</div>`
assert.equal(
rendered,
ReactDOMServer.renderToStaticMarkup(
React.createElement(tmpl, {})
)
)
В package.json описываем, какая версия React’а может быть у пользователя лоадера. В нашем случае, это версии из трёх “веток” — 14, 15 и 16. Делаем это в peerDependencies, а не в dependencies для того, чтобы оставить пользователям возможность выбора версии React’а4
"peerDependencies": {
"react": "^0.14.3 || ^15.6.1 || ^16.0.0"
}
Теперь нам надо подготовить CI окружение (в случае schwartzman, это был5 Travis CI) для прогона тестов. Для этого описываем в конфиге переменную окружения с версиями React’а, против которых гонять тесты
env:
- REACT_VERSION=*
- REACT_VERSION=0.14.3
- REACT_VERSION=15.6.1
- REACT_VERSION=16.0.0
И там же правим install-шаг так, чтобы после стандартной установки зависимостей, устанавливались react и react-dom необходимых версий:
install:
- npm ci
- npm i --no-save "react@$REACT_VERSION" "react-dom@$REACT_VERSION"
И готово. Не так уж и сложнааа, но теперь тесты словят меня, если/когда я поломаю совместимость с прошлыми версиями React’а. А пользователи лоадера смогут получить оптимизации новых версий без необходимости переписывать весь остальной код на новую версию React’а
Опыт
Лоадер несколько лет использовался, чтобы рендерить всякую мелочь в проекте. В конце восемнадцатого-начале девятнадцатого года, подняли-таки инфраструктуру для SSR, так что schwartzmanа удалили из зависимостей… Но, несмотря на то, что лоадер скорее мёртв, приобретенный опыт продолжает жить
Опыт, выражающийся в понимании, что чем меньше код знает о внешнем мире, тем лучше
В знании, что с грамотной спецификацией, задачу можно перенести в контекст, про который её авторы даже не подозревали6
В понимании, что система импортов — это не что-то “данное сверху”, а ещё одно API, которое можно подстроить под себя
И в знании, что тестировать можно не только текущие версии интеграции, но прошлые и будущие7
Может, отпугнуло сообщение на сайте PEGjs, что библиотека “is very much in development”; может, хотелось иметь возможность сгенерировать парсер в Python… ↩︎
Как же приятно иметь оправдание для запрещённого приёма… ↩︎
Для проверки версии лучше не писать свой парсер semver’а, а использовать уже существующий ↩︎
Честно говоря, это делать необязательно, но желательно. Так они смогут сообщить, что лоадер мешает им обновиться, и попросят меня проверить совместимость с новой версией React’а ↩︎
После публикации записи, перенёс CI на Github Actions и немного упростил конфиги для тестирования совместимости ↩︎
Первые коммиты в
mustacheбыли задолго до публичного анонса Реакта, но благодаря подробному описанию и ограниченному синтаксису первого, подружить его со вторым было довольно легко ↩︎Когда в Preact’е поломалась совместимость между версиями, можно было не только починить её, но и добавить тесты, чтобы предотвратить повторение этой проблемы в будущем ↩︎