paperss
Вау, насколько же Google Cloud дружелюбнее, чем AWS…
Решил засунуть я свой инстапейпер в RSS-ридер, потому что Reeder.app я запускать привык, а Instapaper.app — нет. Получилось что-то такое. Дальше будет про процесс написания
У инстапейпера есть официальный фид, но статьи в нём обрезанные. Так же у них есть API, но для доступа к нему надо ждать 🆗 от живого человека
All token requests are reviewed by a human before being activated.
Так что остаётся только генерить свой фид, делая запросы с сессионной кукой сначала к странице instapaper.com/u, а потом к каждой странице статей instapaper.com/read/{id}
Но даже этого недостаточно, потому что на этих страницах нигде нет дат добавления статей, максимум — «Today» и «N months ago». Зато даты есть в их RSS-фиде. Так что надо мержить информацию из фида и из веб-морды (уже переписанное под node@6, о чём дальше):
function getList(cookie) {
return httpRequest({
hostname: "www.instapaper.com",
port: "443",
path: "/u",
method: "GET",
headers: {
Cookie: cookie,
"User-Agent": "node " + process.version
}
}).then(resp => {
const $ = cheerio.load(resp.body);
const rssFeedPath = $('link[type="application/rss+xml"]').attr("href");
return httpRequest({
hostname: "www.instapaper.com",
port: "443",
path: rssFeedPath,
method: "GET"
}).then(rssFeed => {
const articles = // ...
const dates = // ...
const articlesWithDates = // ...
return Promise.all(
articlesWithDates.map(article => getArticle(cookie, article))
);
});
});
}
Немного юзабилити
Сначала скрипт ожидал, что юзер будет иметь при себе сессионную куку и ссылку на RSS-фид. Но так как всё это можно добыть автоматически, то переписал скрипт на использование логина/пароля — они понятнее
Google Cloud
Изначально скрипт просто отдавал сгенеренный фид в stdout, из которого думал создавать файл и загружать его на какой-нибудь now.sh или surge.sh. Но для регулярной загрузки надо заморачиваться с cronом или чем-то аналогичным
Хей, фид нужен только в моменты, когда ридер стучится! Да и никакой базы нет! Пиши лямбды!
С AWS у меня был крохотный опыт, но какой же там интерфейс запутанный, с «ручным» подключением всех нужностей. По своей воле снова туда лезть не буду. Зато на Google Cloud уже был аккаунт…
Насколько же там всё проще. Новый проект -> новая лямбда -> тяни код из этого репозитория на гитхабе -> профит

Даже без репозитория, легко накидать лямбду в вебморде — вот поле для index.js, вот — для package.json
Дописал к скрипту обёртку для обработки запроса и уже привычный сниппет для того, чтобы его можно было и из терминала запускать, и из ноды requireить:
function gcf(req, res) {
return generate().then(result => {
res.status(200).send(result);
});
}
if (require.main === module) {
generate()
.then(result => {
console.log(result);
process.exit(0);
})
.catch(err => {
console.error(err);
process.exit(1);
});
} else {
module.exports = {
generate,
gcf
};
}
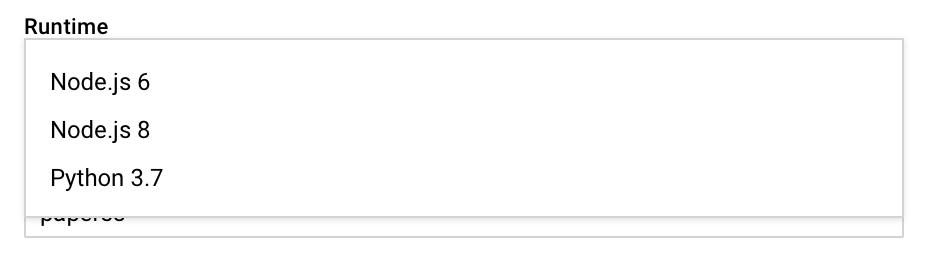
Проблема только в том, что в GCF шестая нода. Так что никаких тебе ...spreadов или async/awaitов. Только .then().then().then()
Но ничего, работает и теперь можно читать всё из Reeder.app 👍
UPD 2018-07-23: cтоило только переписать всё на node@6, так появилась опция Runtime с Node.js 8 и Python 3.7. async/await all the things!